3. Análisis Exploratorio de Datos#
En este capítulo se utilizarán las siguientes librerías de Python:
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
3.1. Introducción#
En el Análisis Exploratorio de Datos (AED) intentaremos entender de qué se componen las observaciones que tenemos entre manos con los objetivos de:
Limpiar el conjunto de datos e identificar problemas potenciales en las mediciones disponibles
Formular hipótesis sobre la población (por ej. asociaciones entre variables)
Guiar las decisiones de modelado posteriores
Para lograr esto usamos herramientas como:
Estadísticos resumen: Medidas numéricas (métricas) que resumen propiedades relevantes de los datos
Gráficos de visualización: Representaciones gráficas que permiten relevar valores típicos y “extraños”, asociaciones entre variables
3.2. Caracterización de Observaciones Univariadas#
3.2.1. Entendiendo la distribución de los datos#
El primer paso en el análisis de cualquier variable es comprender cómo se distribuyen sus valores. Esto implica examinar la frecuencia de ocurrencia de diferentes valores o rangos de valores dentro de los valores observados.
3.2.1.1. Histogramas#
Los histogramas son la herramienta principal para visualizar la distribución de variables continuas y discretas. Muestran la frecuencia o recuento de observaciones dentro de intervalos específicos (bins).
# Generar datos de muestra
np.random.seed(42)
datos = np.random.normal(100, 15, 1000)
# Crear histograma
plt.figure(figsize=(10, 6))
plt.hist(datos, bins=30, density=True, alpha=0.7, color='skyblue', edgecolor='black')
plt.title('Histograma de Datos de Muestra')
plt.xlabel('Valor')
plt.ylabel('Densidad')
plt.grid(True, alpha=0.3)
plt.show()
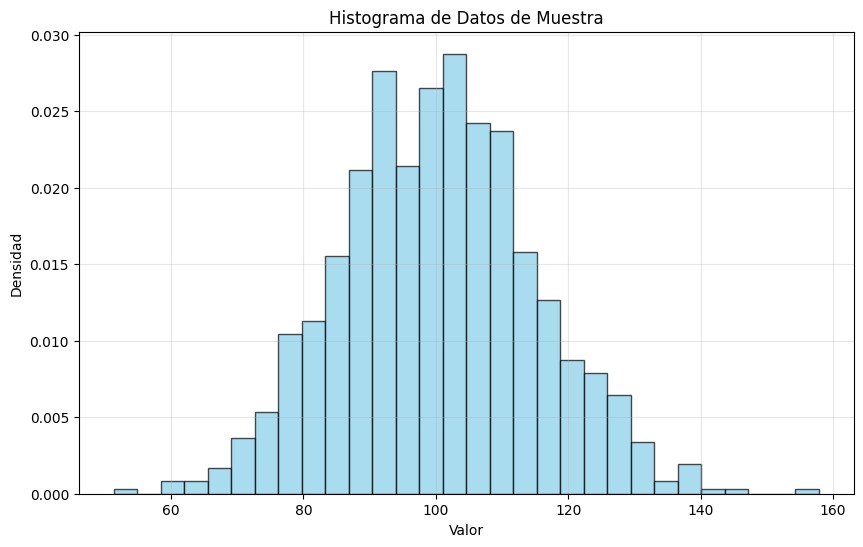
Consideraciones clave para histogramas:
Sensibilidad al ancho del bin: La elección del ancho del bin afecta significativamente la apariencia del histograma
Regla de Sturges: Una guía común para elegir el número de bins: \(K = 1 + 3.222 \log_{10}(N)\), donde \(N\) es el tamaño de la muestra
Cobertura: Todos los puntos de datos deben estar incluidos en los bins
3.2.1.2. Estimación de densidad de Kernel#
La estimación de densidad por kernel proporciona una estimación suave de la función de densidad de probabilidad, efectivamente “suavizando” el histograma.
# Crear gráfico de densidad por kernel
plt.figure(figsize=(10, 6))
sns.histplot(datos, kde=True, stat='density', alpha=0.7)
plt.title('Histograma con Estimación de Densidad por Kernel')
plt.xlabel('Valor')
plt.ylabel('Densidad')
plt.grid(True, alpha=0.3)
plt.show()
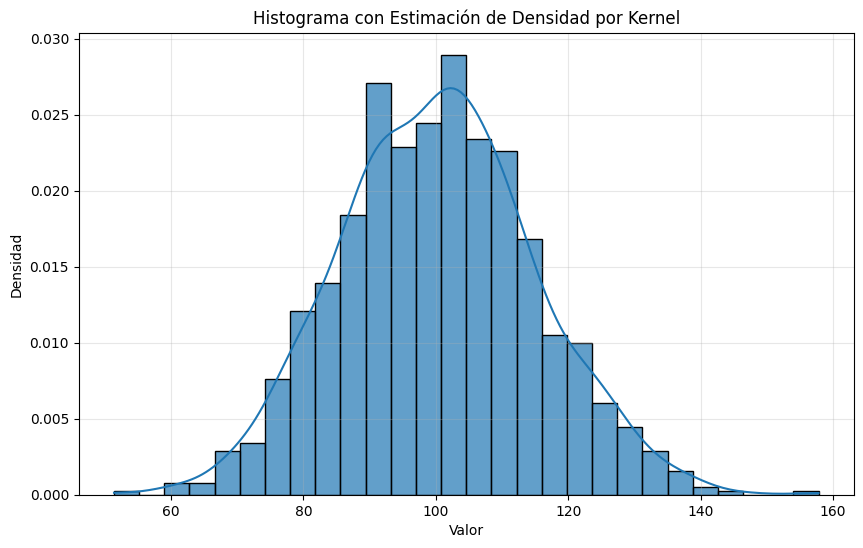
El parámetro de ancho de banda controla la suavidad de la estimación de densidad por kernel - anchos de banda más amplios producen curvas más suaves pero pueden ocultar detalles importantes.
3.2.1.3. Función de distribución acumulada empírica#
La función de distribución acumulada empírica (FDAE) muestra la proporción de puntos de datos menores o iguales a un valor dado:
# Crear gráfico de FDAE
plt.figure(figsize=(10, 6))
datos_ordenados = np.sort(datos)
valores_y = np.arange(1, len(datos_ordenados) + 1) / len(datos_ordenados)
plt.plot(datos_ordenados, valores_y, linewidth=2)
plt.title('Función de Distribución Acumulada Empírica')
plt.xlabel('Valor')
plt.ylabel('Probabilidad Acumulada')
plt.grid(True, alpha=0.3)
plt.show()
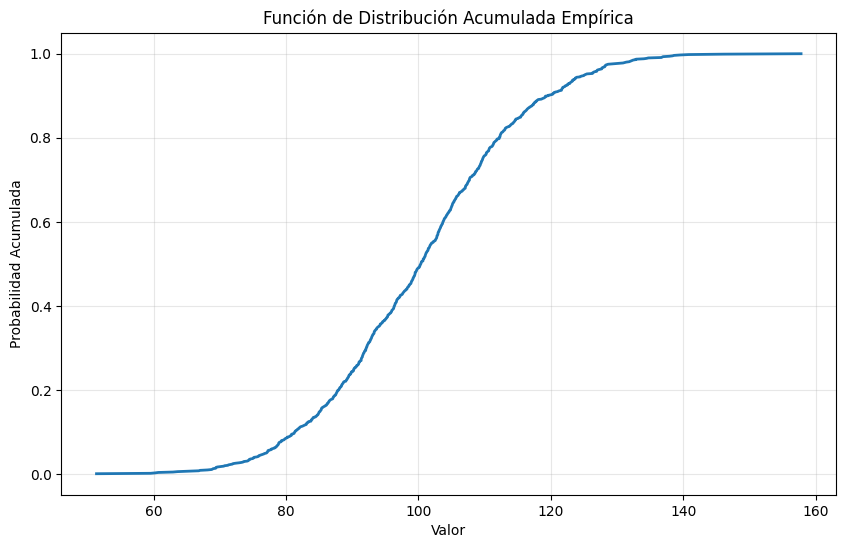
3.2.1.4. Percentiles y Cuartiles#
Los percentiles describen la posición relativa de los valores dentro del conjunto de datos.
El percentil \(p\) es el valor por debajo del cual cae el \(p\%\) de los datos:
Primer cuartil (Q1): percentil 25
Mediana (Q2): percentil 50
Tercer cuartil (Q3): percentil 75
# Calcular cuartiles
q1 = np.percentile(datos, 25)
q2 = np.percentile(datos, 50) # mediana
q3 = np.percentile(datos, 75)
print(f"Q1 (percentil 25): {q1:.2f}")
print(f"Q2 (percentil 50/mediana): {q2:.2f}")
print(f"Q3 (percentil 75): {q3:.2f}")
Q1 (percentil 25): 90.29
Q2 (percentil 50/mediana): 100.38
Q3 (percentil 75): 109.72
3.2.1.5. Diagramas de Caja#
Los diagramas de caja proporcionan un resumen visual de la distribución usando cuartiles:
# Crear diagrama de caja
plt.figure(figsize=(10, 6))
plt.subplot(1, 2, 1)
plt.boxplot(datos, patch_artist=True, boxprops=dict(facecolor='lightblue'))
plt.title('Diagrama de Caja')
plt.ylabel('Valor')
# Crear diagrama de caja horizontal con observaciones individuales
plt.subplot(1, 2, 2)
sns.boxplot(y=datos, orient='v')
sns.stripplot(y=datos, color='red', alpha=0.5, size=3)
plt.title('Diagrama de Caja con Puntos de Datos')
plt.ylabel('Valor')
plt.tight_layout()
plt.show()
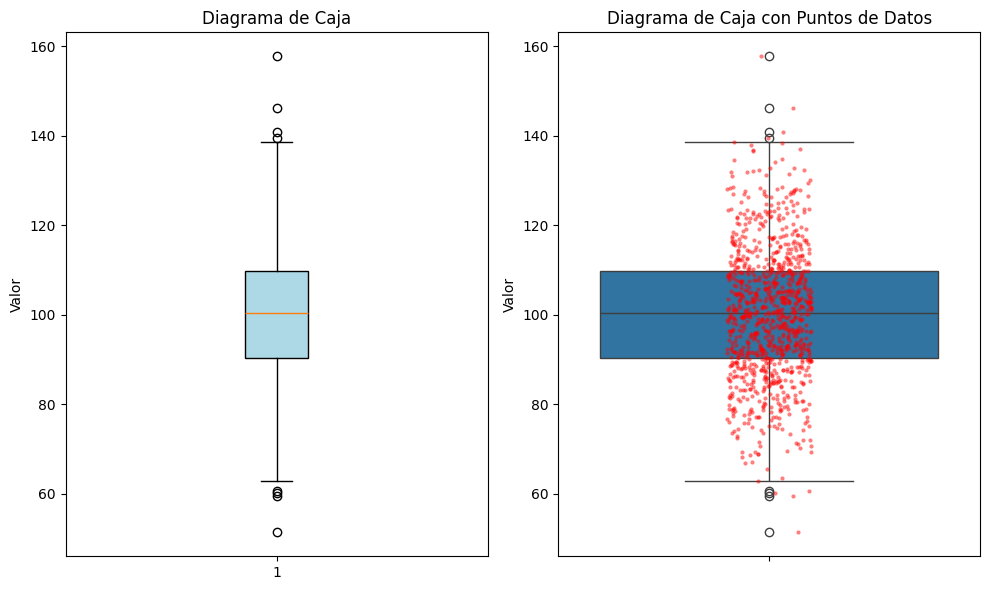
El diagrama de caja muestra:
Caja: Rango intercuartil (RIC) desde Q1 hasta Q3
Línea en la caja: Mediana (Q2)
Bigotes: Se extienden hasta 1.5 × RIC más allá de los cuartiles o hasta los extremos de los datos
Valores atípicos: Puntos más allá de los bigotes
3.2.2. Medidas de Tendencia Central#
Las medidas de tendencia central describen el valor “típico” o representativo alrededor del cual se agrupan los datos.
3.2.2.1. Media (Promedio)#
La media muestral es el promedio aritmético de todas las observaciones:
Propiedades de la media:
Minimiza la suma de desviaciones cuadradas de los puntos de datos
Representa el “centro de gravedad” de los datos
Puede no ser un valor posible para datos discretos
No tiene sentido para datos categóricos nominales
Sensible a valores atípicos
# Calcular y mostrar la media
media_muestral = np.mean(datos)
print(f"Media muestral: {media_muestral:.2f}")
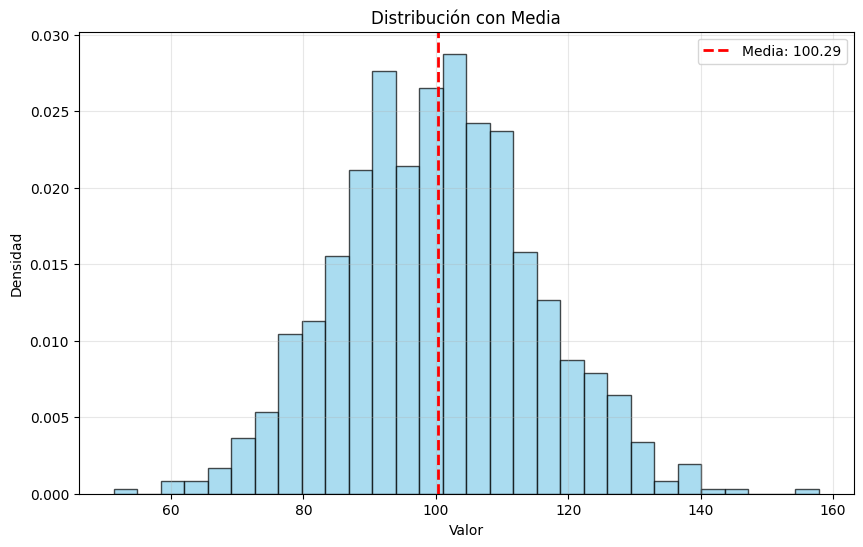
# Visualizar la media en el histograma
plt.figure(figsize=(10, 6))
plt.hist(datos, bins=30, density=True, alpha=0.7, color='skyblue', edgecolor='black')
plt.axvline(media_muestral, color='red', linestyle='--', linewidth=2,
label=f'Media: {media_muestral:.2f}')
plt.title('Distribución con Media')
plt.xlabel('Valor')
plt.ylabel('Densidad')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
Media muestral: 100.29
3.2.2.2. Mediana#
La mediana es el valor medio cuando los datos están ordenados - divide el conjunto de datos en dos mitades iguales.
Propiedades de la mediana:
Minimiza la suma de desviaciones absolutas de los puntos de datos
Siempre corresponde a un valor de datos real
No tiene sentido para datos categóricos nominales
Menos sensible a valores atípicos que la media
Más representativa del punto de datos “típico” en distribuciones sesgadas
# Demostrar sensibilidad de mediana vs media a valores atípicos
datos_normales = [4.2, 5.3, 3.8, 7.9, 6.4, 3.8, 5.1]
con_atipico = datos_normales + [20.3]
print("Sin valor atípico:")
print(f"Media: {np.mean(datos_normales):.2f}")
print(f"Mediana: {np.median(datos_normales):.2f}")
print("\nCon valor atípico:")
print(f"Media: {np.mean(con_atipico):.2f}")
print(f"Mediana: {np.median(con_atipico):.2f}")
Sin valor atípico:
Media: 5.21
Mediana: 5.10
Con valor atípico:
Media: 7.10
Mediana: 5.20
3.2.2.3. Moda#
La moda es el valor que ocurre con mayor frecuencia en el conjunto de datos.
Propiedades de la moda:
Siempre corresponde a un valor de datos real para variables discretas y categóricas
Para datos continuos, puede aproximarse usando histogramas o estimación de densidad por kernel
Una distribución puede tener múltiples modas (multimodal) o no tener moda clara
# Ejemplo con datos discretos
datos_discretos = [1, 2, 2, 3, 3, 3, 4, 4, 5]
from scipy import stats
resultado_moda = stats.mode(datos_discretos)
print(f"Moda: {resultado_moda.mode}, Frecuencia: {resultado_moda.count}")
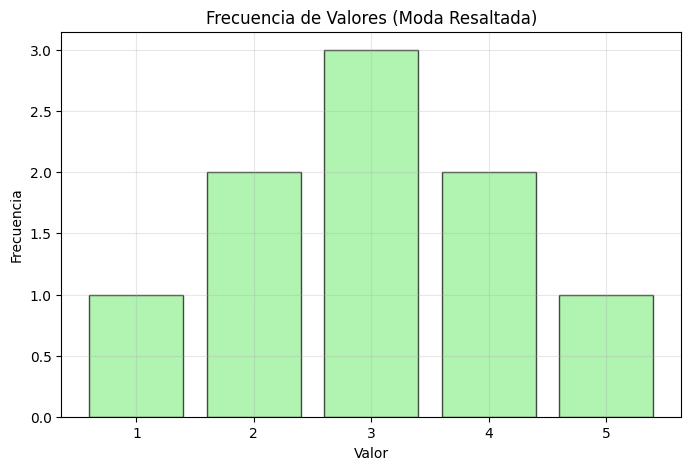
# Visualizar la moda
plt.figure(figsize=(8, 5))
unicos, frecuencias = np.unique(datos_discretos, return_counts=True)
plt.bar(unicos, frecuencias, alpha=0.7, color='lightgreen', edgecolor='black')
plt.title('Frecuencia de Valores (Moda Resaltada)')
plt.xlabel('Valor')
plt.ylabel('Frecuencia')
plt.grid(True, alpha=0.3)
plt.show()
Moda: 3, Frecuencia: 3
3.2.3. Medidas de Dispersión#
Las medidas de dispersión cuantifican qué tan dispersos están los puntos de datos alrededor de la tendencia central.
3.2.3.1. Varianza y Desviación Estándar#
Varianza muestral: Promedio de las desviaciones cuadradas de la media: $\(s^2 = \frac{1}{n-1}\sum_{i=1}^{n}(x_i - \bar{x})^2\)$
Desviación estándar: Raíz cuadrada de la varianza: $\(s = \sqrt{s^2}\)$
# Calcular varianza y desviación estándar
varianza = np.var(datos, ddof=1) # ddof=1 para varianza muestral
desv_estandar = np.std(datos, ddof=1) # ddof=1 para desviación estándar muestral
print(f"Varianza muestral: {varianza:.2f}")
print(f"Desviación estándar muestral: {desv_estandar:.2f}")
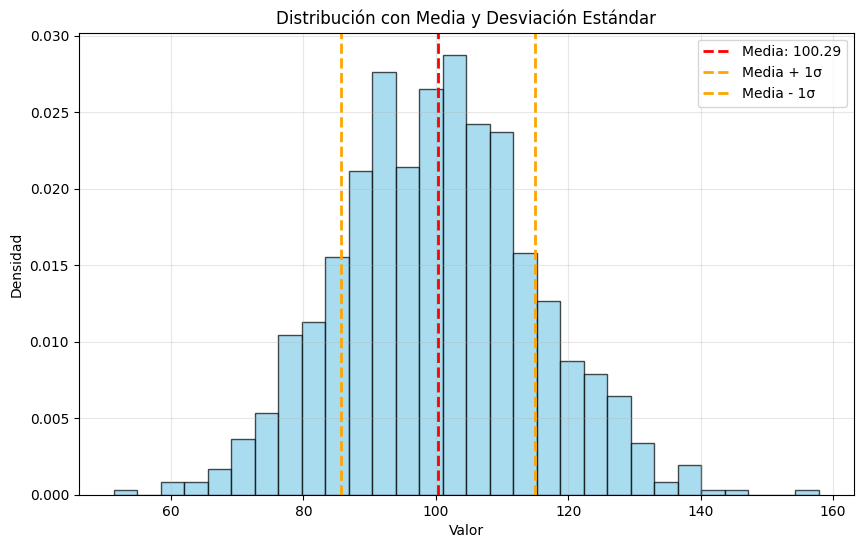
# Visualizar desviación estándar
plt.figure(figsize=(10, 6))
plt.hist(datos, bins=30, density=True, alpha=0.7, color='skyblue', edgecolor='black')
plt.axvline(media_muestral, color='red', linestyle='--', linewidth=2,
label=f'Media: {media_muestral:.2f}')
plt.axvline(media_muestral + desv_estandar, color='orange', linestyle='--', linewidth=2,
label=f'Media + 1σ')
plt.axvline(media_muestral - desv_estandar, color='orange', linestyle='--', linewidth=2,
label=f'Media - 1σ')
plt.title('Distribución con Media y Desviación Estándar')
plt.xlabel('Valor')
plt.ylabel('Densidad')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
Varianza muestral: 215.74
Desviación estándar muestral: 14.69
3.2.3.2. Desviación Media Absoluta#
Promedio de las desviaciones absolutas de la media: $\(\text{DMA} = \frac{1}{n}\sum_{i=1}^{n}|x_i - \bar{x}|\)$
# Calcular desviación media absoluta
dma = np.mean(np.abs(datos - media_muestral))
print(f"Desviación Media Absoluta: {dma:.2f}")
Desviación Media Absoluta: 11.69
3.2.3.3. Rango Intercuartil (RIC)#
El RIC mide la dispersión del 50% central de los datos: $\(\text{RIC} = Q_3 - Q_1\)$
# Calcular RIC
ric = q3 - q1
print(f"Rango Intercuartil (RIC): {ric:.2f}")
Rango Intercuartil (RIC): 19.43
3.2.4. Intervalos de confianza#
xxx
3.2.4.1. Intervalos de confianza centados#
3.2.4.2. Intervalos de máxima densidad de probabilidad#
3.3. Caracterización de Asociaciones Entre Variables#
3.3.1. Análisis de Datos Bivariados#
Al trabajar con dos variables simultáneamente, estamos interesados en comprender su distribución conjunta y posibles relaciones.
3.3.1.1. Diagramas de Dispersión para Variables Continuas#
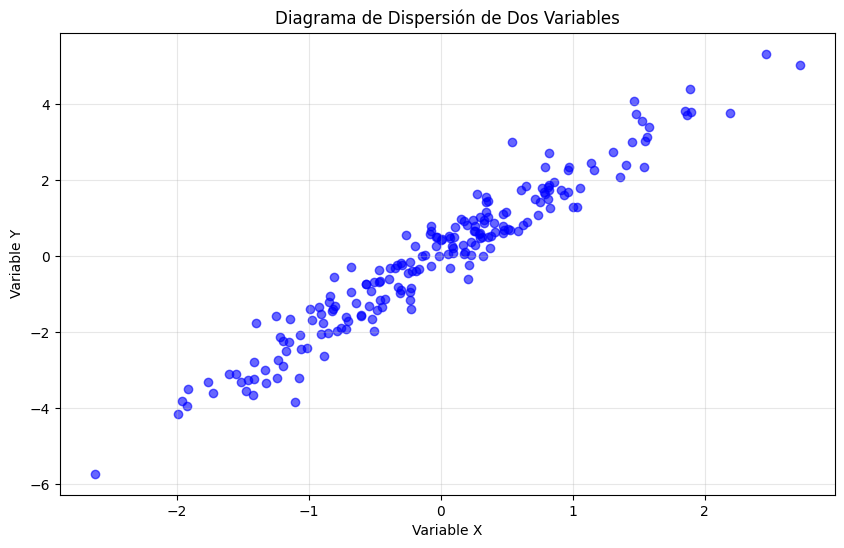
Los diagramas de dispersión son la herramienta principal para visualizar relaciones entre dos variables continuas:
# Generar datos correlacionados
np.random.seed(42)
x = np.random.normal(0, 1, 200)
y = 2 * x + np.random.normal(0, 0.5, 200)
# Crear diagrama de dispersión
plt.figure(figsize=(10, 6))
plt.scatter(x, y, alpha=0.6, color='blue')
plt.title('Diagrama de Dispersión de Dos Variables')
plt.xlabel('Variable X')
plt.ylabel('Variable Y')
plt.grid(True, alpha=0.3)
plt.show()
3.3.1.2. Análisis de Correlación#
El coeficiente de correlación de Pearson mide la asociación lineal entre dos variables:
Donde \(s_X\) y \(s_Y\) son las desviaciones estándar muestrales de X e Y respectivamente.
# Calcular correlación
correlacion = np.corrcoef(x, y)[0, 1]
print(f"Coeficiente de correlación de Pearson: {correlacion:.3f}")
# Visualizar correlación
plt.figure(figsize=(10, 6))
plt.scatter(x, y, alpha=0.6, color='blue')
plt.title(f'Diagrama de Dispersión con Correlación r = {correlacion:.3f}')
plt.xlabel('Variable X')
plt.ylabel('Variable Y')
# Agregar línea de tendencia
z = np.polyfit(x, y, 1)
p = np.poly1d(z)
plt.plot(x, p(x), "r--", alpha=0.8, linewidth=2)
plt.grid(True, alpha=0.3)
plt.show()
Coeficiente de correlación de Pearson: 0.968
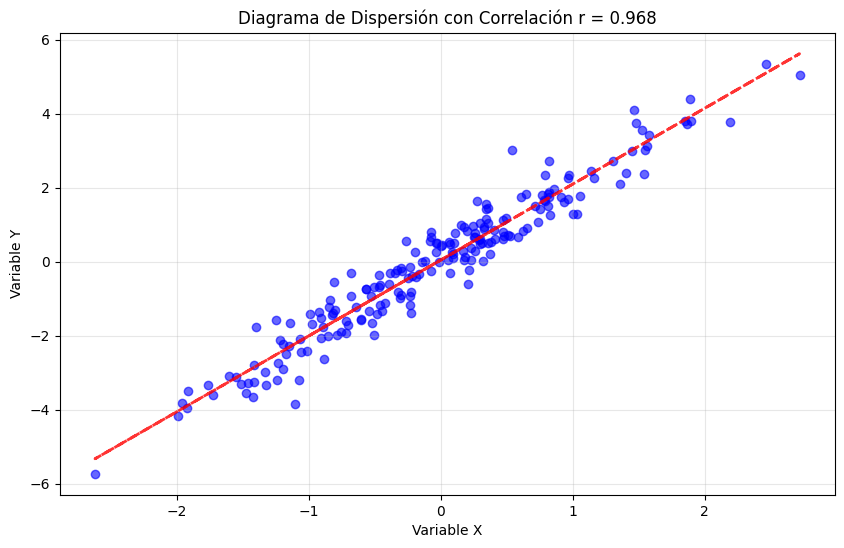
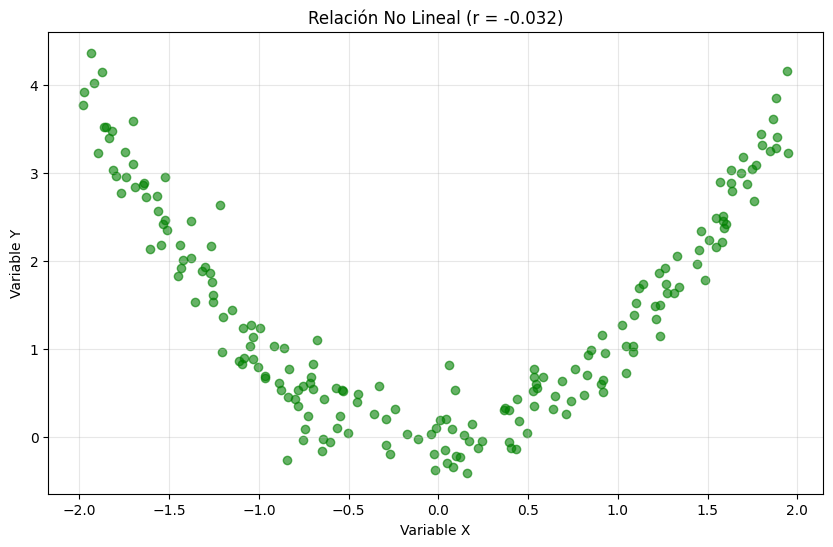
3.3.1.3. Consideraciones Importantes para la Correlación#
Correlación cero no implica ausencia de relación - solo ausencia de relación lineal:
# Ejemplo de relación no lineal con correlación cero
np.random.seed(42)
x_no_lineal = np.random.uniform(-2, 2, 200)
y_no_lineal = x_no_lineal**2 + np.random.normal(0, 0.3, 200)
correlacion_no_lineal = np.corrcoef(x_no_lineal, y_no_lineal)[0, 1]
plt.figure(figsize=(10, 6))
plt.scatter(x_no_lineal, y_no_lineal, alpha=0.6, color='green')
plt.title(f'Relación No Lineal (r = {correlacion_no_lineal:.3f})')
plt.xlabel('Variable X')
plt.ylabel('Variable Y')
plt.grid(True, alpha=0.3)
plt.show()
La misma correlación puede representar relaciones muy diferentes (Cuarteto de Anscombe):
# Demostración del Cuarteto de Anscombe
# Conjunto de datos 1: Relación lineal
x1 = np.array([10, 8, 13, 9, 11, 14, 6, 4, 12, 7, 5])
y1 = np.array([8.04, 6.95, 7.58, 8.81, 8.33, 9.96, 7.24, 4.26, 10.84, 4.82, 5.68])
# Conjunto de datos 2: Relación no lineal
x2 = np.array([10, 8, 13, 9, 11, 14, 6, 4, 12, 7, 5])
y2 = np.array([9.14, 8.14, 8.74, 8.77, 9.26, 8.10, 6.13, 3.10, 9.13, 7.26, 4.74])
# Calcular correlaciones
r1 = np.corrcoef(x1, y1)[0, 1]
r2 = np.corrcoef(x2, y2)[0, 1]
# Graficar ambos conjuntos de datos
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
ax1.scatter(x1, y1, color='blue', alpha=0.7)
ax1.set_title(f'Conjunto de Datos 1: r = {r1:.3f}')
ax1.set_xlabel('X')
ax1.set_ylabel('Y')
ax1.grid(True, alpha=0.3)
ax2.scatter(x2, y2, color='red', alpha=0.7)
ax2.set_title(f'Conjunto de Datos 2: r = {r2:.3f}')
ax2.set_xlabel('X')
ax2.set_ylabel('Y')
ax2.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
print(f"A pesar de patrones muy diferentes, ambos conjuntos tienen correlaciones similares:")
print(f"Correlación conjunto 1: {r1:.3f}")
print(f"Correlación conjunto 2: {r2:.3f}")
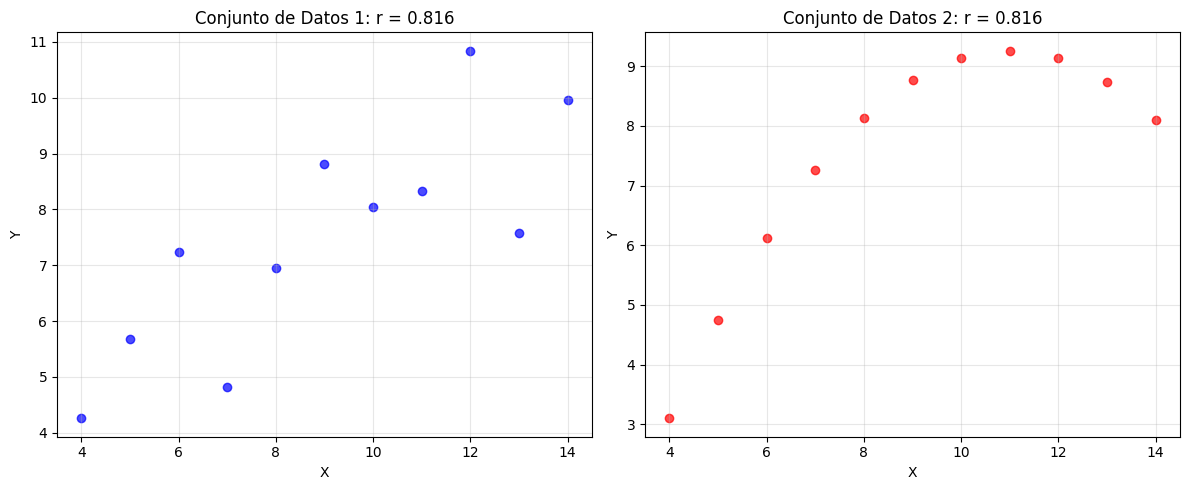
A pesar de patrones muy diferentes, ambos conjuntos tienen correlaciones similares:
Correlación conjunto 1: 0.816
Correlación conjunto 2: 0.816
3.3.2. Variables Continuas vs Categóricas#
Cuando una variable es continua y la otra es categórica, típicamente usamos:
# Generar datos de muestra
np.random.seed(42)
categorias = ['A', 'B', 'C', 'D']
dict_datos = {}
for cat in categorias:
# Diferentes medias para cada categoría
valor_medio = np.random.uniform(10, 30)
dict_datos[cat] = np.random.normal(valor_medio, 5, 100)
# Crear DataFrame
df_cont_cat = pd.DataFrame(dict([(k, pd.Series(v)) for k, v in dict_datos.items()]))
df_derretido = df_cont_cat.melt(var_name='Categoría', value_name='Valor')
# Comparación con diagrama de caja
plt.figure(figsize=(10, 6))
sns.boxplot(data=df_derretido, x='Categoría', y='Valor')
plt.title('Variable Continua por Categoría')
plt.grid(True, alpha=0.3)
plt.show()
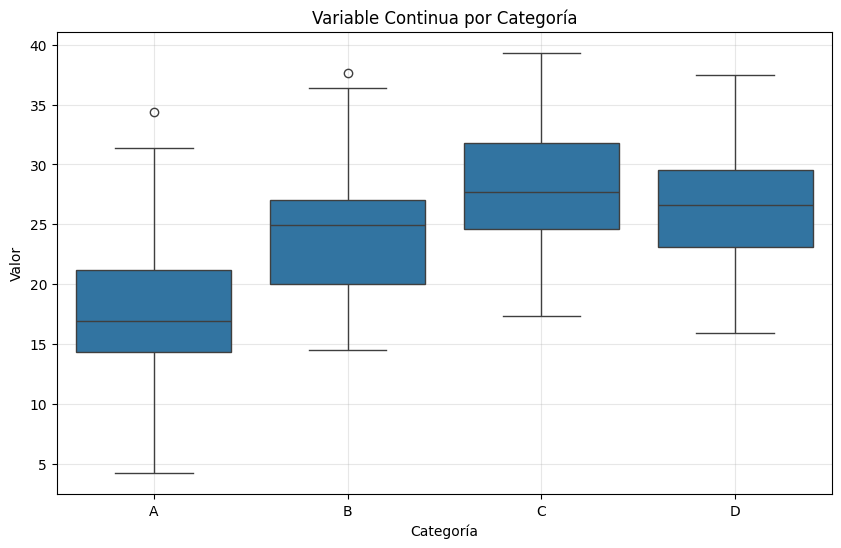
3.3.3. Variables Categóricas vs Categóricas#
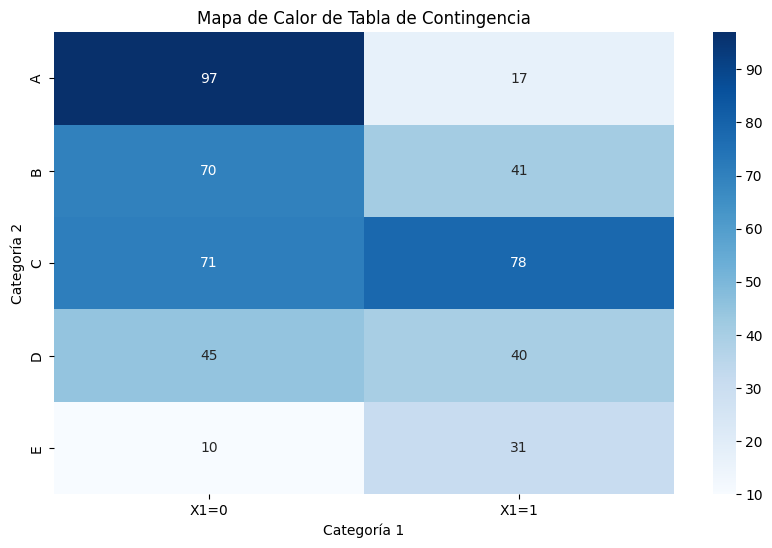
Para dos variables categóricas, usamos tablas de contingencia y visualizaciones asociadas:
# Crear datos categóricos de muestra
np.random.seed(42)
categoria1 = np.random.choice(['X1=0', 'X1=1'], 500, p=[0.6, 0.4])
categoria2 = []
for cat in categoria1:
if cat == 'X1=0':
categoria2.append(np.random.choice(['A', 'B', 'C', 'D', 'E'],
p=[0.3, 0.25, 0.25, 0.15, 0.05]))
else:
categoria2.append(np.random.choice(['A', 'B', 'C', 'D', 'E'],
p=[0.1, 0.15, 0.35, 0.25, 0.15]))
# Crear tabla de contingencia
tabla_contingencia = pd.crosstab(categoria2, categoria1)
print("Tabla de Contingencia (Frecuencias):")
print(tabla_contingencia)
# Crear tabla de proporciones
tabla_proporciones = pd.crosstab(categoria2, categoria1, normalize='columns')
print("\nTabla de Proporciones:")
print(tabla_proporciones.round(3))
# Visualizar con mapa de calor
plt.figure(figsize=(10, 6))
sns.heatmap(tabla_contingencia, annot=True, cmap='Blues', fmt='d')
plt.title('Mapa de Calor de Tabla de Contingencia')
plt.ylabel('Categoría 2')
plt.xlabel('Categoría 1')
plt.show()
Tabla de Contingencia (Frecuencias):
col_0 X1=0 X1=1
row_0
A 97 17
B 70 41
C 71 78
D 45 40
E 10 31
Tabla de Proporciones:
col_0 X1=0 X1=1
row_0
A 0.331 0.082
B 0.239 0.198
C 0.242 0.377
D 0.154 0.193
E 0.034 0.150
3.4. Visualización de Series Temporales#
Cuando una de las variables representa tiempo, las técnicas de visualización especiales ayudan a identificar patrones temporales.
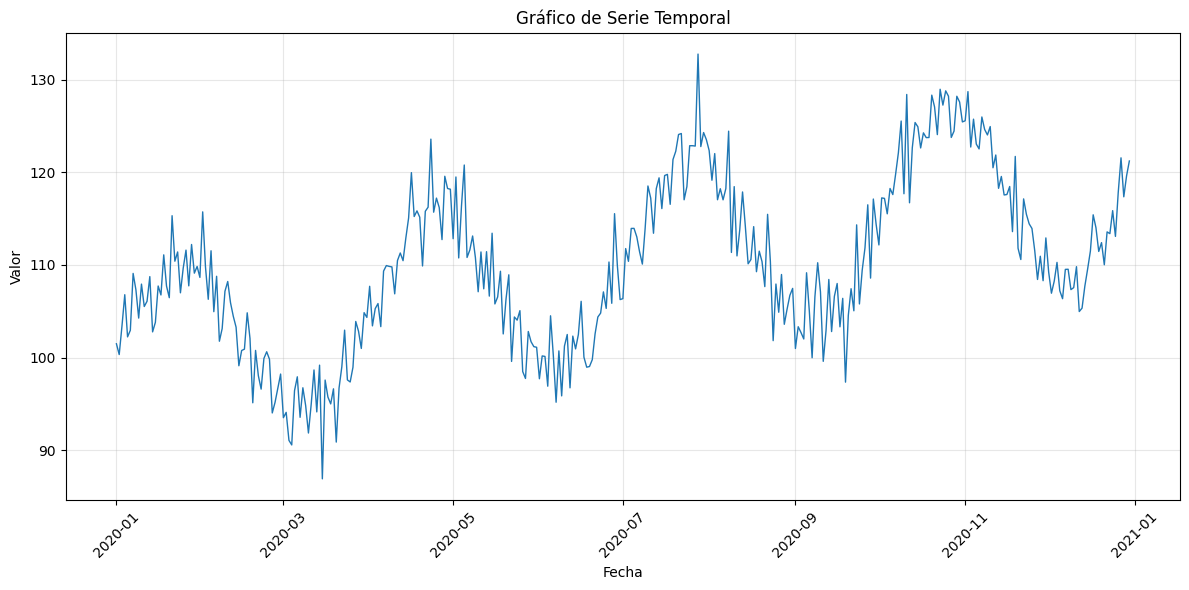
3.4.1. Gráficos Básicos de Series Temporales#
# Generar datos de serie temporal de muestra
fechas = pd.date_range('2020-01-01', periods=365, freq='D')
np.random.seed(42)
# Crear tendencia + estacionalidad + ruido
tendencia = np.linspace(100, 120, 365)
estacional = 10 * np.sin(2 * np.pi * np.arange(365) / 365.25 * 4) # Patrón trimestral
ruido = np.random.normal(0, 3, 365)
valores = tendencia + estacional + ruido
datos_st = pd.DataFrame({'fecha': fechas, 'valor': valores})
# Gráfico básico de serie temporal
plt.figure(figsize=(12, 6))
plt.plot(datos_st['fecha'], datos_st['valor'], linewidth=1)
plt.title('Gráfico de Serie Temporal')
plt.xlabel('Fecha')
plt.ylabel('Valor')
plt.grid(True, alpha=0.3)
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
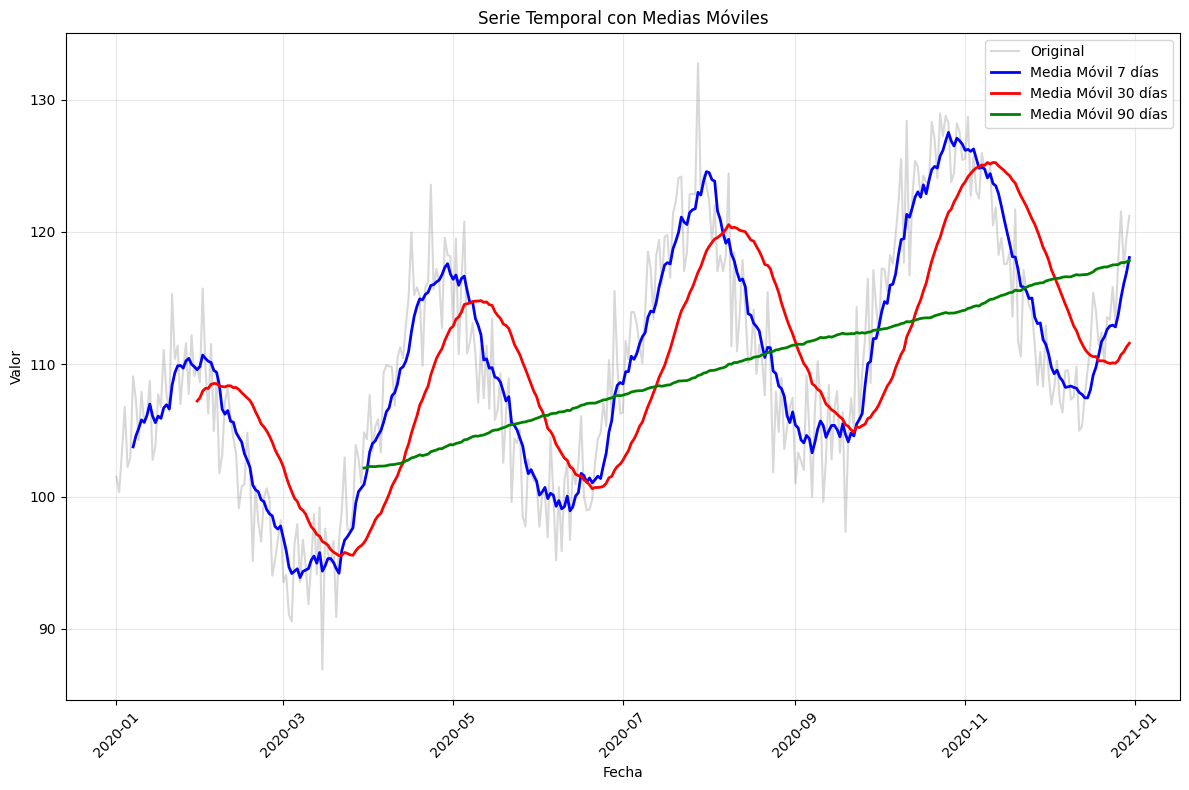
3.4.2. Medias Móviles#
Las medias móviles ayudan a detectar tendencias suavizando las fluctuaciones a corto plazo:
# Calcular medias móviles
tamaños_ventana = [7, 30, 90]
plt.figure(figsize=(12, 8))
plt.plot(datos_st['fecha'], datos_st['valor'], alpha=0.3, label='Original', color='gray')
colores = ['blue', 'red', 'green']
for i, ventana in enumerate(tamaños_ventana):
datos_st[f'MM_{ventana}'] = datos_st['valor'].rolling(window=ventana).mean()
plt.plot(datos_st['fecha'], datos_st[f'MM_{ventana}'],
label=f'Media Móvil {ventana} días',
color=colores[i], linewidth=2)
plt.title('Serie Temporal con Medias Móviles')
plt.xlabel('Fecha')
plt.ylabel('Valor')
plt.legend()
plt.grid(True, alpha=0.3)
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
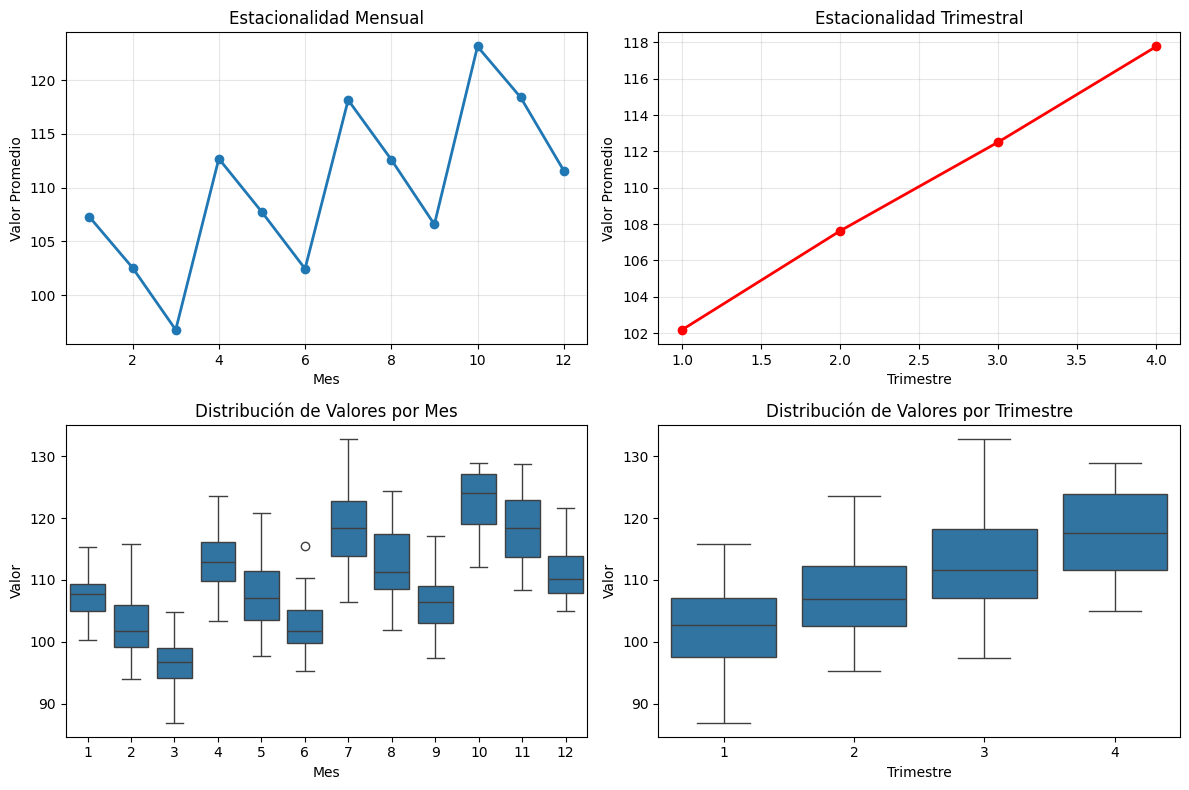
3.4.3. Análisis de Estacionalidad#
Los gráficos de estacionalidad ayudan a identificar patrones recurrentes:
# Agregar información de mes y trimestre
datos_st['mes'] = datos_st['fecha'].dt.month
datos_st['trimestre'] = datos_st['fecha'].dt.quarter
# Gráfico de estacionalidad mensual
plt.figure(figsize=(12, 8))
plt.subplot(2, 2, 1)
promedio_mensual = datos_st.groupby('mes')['valor'].mean()
plt.plot(promedio_mensual.index, promedio_mensual.values, 'o-', linewidth=2)
plt.title('Estacionalidad Mensual')
plt.xlabel('Mes')
plt.ylabel('Valor Promedio')
plt.grid(True, alpha=0.3)
# Gráfico de estacionalidad trimestral
plt.subplot(2, 2, 2)
promedio_trimestral = datos_st.groupby('trimestre')['valor'].mean()
plt.plot(promedio_trimestral.index, promedio_trimestral.values, 'o-', linewidth=2, color='red')
plt.title('Estacionalidad Trimestral')
plt.xlabel('Trimestre')
plt.ylabel('Valor Promedio')
plt.grid(True, alpha=0.3)
# Diagrama de caja por mes
plt.subplot(2, 2, 3)
sns.boxplot(data=datos_st, x='mes', y='valor')
plt.title('Distribución de Valores por Mes')
plt.xlabel('Mes')
plt.ylabel('Valor')
# Diagrama de caja por trimestre
plt.subplot(2, 2, 4)
sns.boxplot(data=datos_st, x='trimestre', y='valor')
plt.title('Distribución de Valores por Trimestre')
plt.xlabel('Trimestre')
plt.ylabel('Valor')
plt.tight_layout()
plt.show()
3.4.4. Visualización de Descomposición#
La descomposición de series temporales separa los componentes de tendencia, estacionalidad y residuos:
from statsmodels.tsa.seasonal import seasonal_decompose
# Realizar descomposición
descomposicion = seasonal_decompose(datos_st['valor'], model='additive', period=90)
# Graficar descomposición
fig, axes = plt.subplots(4, 1, figsize=(12, 10))
datos_st['valor'].plot(ax=axes[0], title='Original')
axes[0].set_ylabel('Valor')
descomposicion.trend.plot(ax=axes[1], title='Tendencia')
axes[1].set_ylabel('Tendencia')
descomposicion.seasonal.plot(ax=axes[2], title='Estacional')
axes[2].set_ylabel('Estacional')
descomposicion.resid.plot(ax=axes[3], title='Residuos')
axes[3].set_ylabel('Residuos')
axes[3].set_xlabel('Fecha')
plt.tight_layout()
plt.show()
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
Cell In[22], line 1
----> 1 from statsmodels.tsa.seasonal import seasonal_decompose
3 # Realizar descomposición
4 descomposicion = seasonal_decompose(datos_st['valor'], model='additive', period=90)
ModuleNotFoundError: No module named 'statsmodels'
3.5. Resumen#
Este capítulo cubrió los conceptos y técnicas fundamentales del Análisis Exploratorio de Datos:
3.5.1. Análisis Univariado#
Distribuciones de frecuencia: Histogramas, estimación de densidad por kernel, y funciones de distribución acumulada empírica
Tendencia central: Media, mediana y moda con sus respectivas propiedades y casos de uso
Medidas de posición: Percentiles y cuartiles, visualizados mediante diagramas de caja
Medidas de dispersión: Varianza, desviación estándar, desviación media absoluta y rango intercuartil
3.5.2. Análisis Multivariado#
Relaciones continuas-continuas: Diagramas de dispersión y análisis de correlación
Relaciones continuas-categóricas: Diagramas de caja y comparaciones de distribuciones
Relaciones categóricas-categóricas: Tablas de contingencia y análisis de proporciones
3.5.3. Análisis de Series Temporales#
Patrones temporales: Gráficos básicos de series temporales e identificación de tendencias
Técnicas de suavizado: Medias móviles para detectar tendencias subyacentes
Estacionalidad: Identificación y visualización de patrones recurrentes
Descomposición: Separación de componentes de tendencia, estacionalidad y residuos
3.5.4. Conclusiones Clave#
Siempre visualice sus datos - los resúmenes numéricos por sí solos pueden ser engañosos
Considere el tipo de datos - diferentes técnicas se aplican a variables continuas vs categóricas
Tenga en cuenta los valores atípicos - pueden afectar significativamente las estadísticas resumen
La correlación no implica causalidad - y correlación cero no significa ausencia de relación
Múltiples perspectivas - use varias técnicas de visualización para comprender completamente sus datos
Estas técnicas de AED forman la base para aplicaciones más avanzadas de modelado estadístico y aprendizaje automático. Ayudan a asegurar la calidad de los datos, guían las decisiones de ingeniería de características y proporcionan información que informa todo el flujo de trabajo de ciencia de datos.